Development Process
The development of the Procedural Quest Generation system was carried out in three major phases—research and planning, iterative design and implementation, and evaluation and validation. Each phase contributed to refining the system's capabilities and ensuring robust integration with the Unity engine.
📚 Phase 1: Initial Research & Planning
The project began with an in-depth exploration of best practices in quest design. This research drew insights from academic literature and industry analyses, including resources from Game Maker’s Toolkit, Extra Credits, and The Architect of Games. The focus was on understanding what makes quests engaging—multi-part narratives, contextual objectives, and character-driven storytelling.
Simultaneously, foundational technologies were selected. Llama3.1 was chosen as the primary language model, deployed locally via Ollama. The backend was developed using Python, with early prototypes testing basic text generation and schema adherence.
import ollama
def generate_quest(template_info, questline_example, objective_info):
brainstorming_system_prompt = (f"You are a Quest Designer at a Game studio.\n"
f"You have been tasked with creating compelling Side-Quests for a Role-Playing Game.\n"
f"The game is set in a Fantasy setting.\n"
f"Create engaging and creative questlines that enhance the player's experience and provide meaningful content.\n"
f"You should create multi-part questlines.\n"
f"Try to compelling narratives that deviate from the norms.\n"
f"\n###\n"
f"The questline generated should follow the \"template\" given below:\n"
f"{template_info}\n"
f"Given below is an example. Use it for reference only:\n"
f"{questline_example}\n"
f"\n###\n"
f"Each quest of the questline should be of a type otlined in the \"quest_objectives\" below:\n"
f"{objective_info}\n"
f"\n###\n"
f"\nGive a name to the questline as a whole.\n"
f"\nDescribe each quest in the format given:\n"
f"Name:\nType:\nGoal:\nDescription:\n")
response = ollama.chat(model="llama3", messages=[
{
"role": "system",
"content": brainstorming_system_prompt
}
], options={"temperature": 2})
return response["message"]["content"]
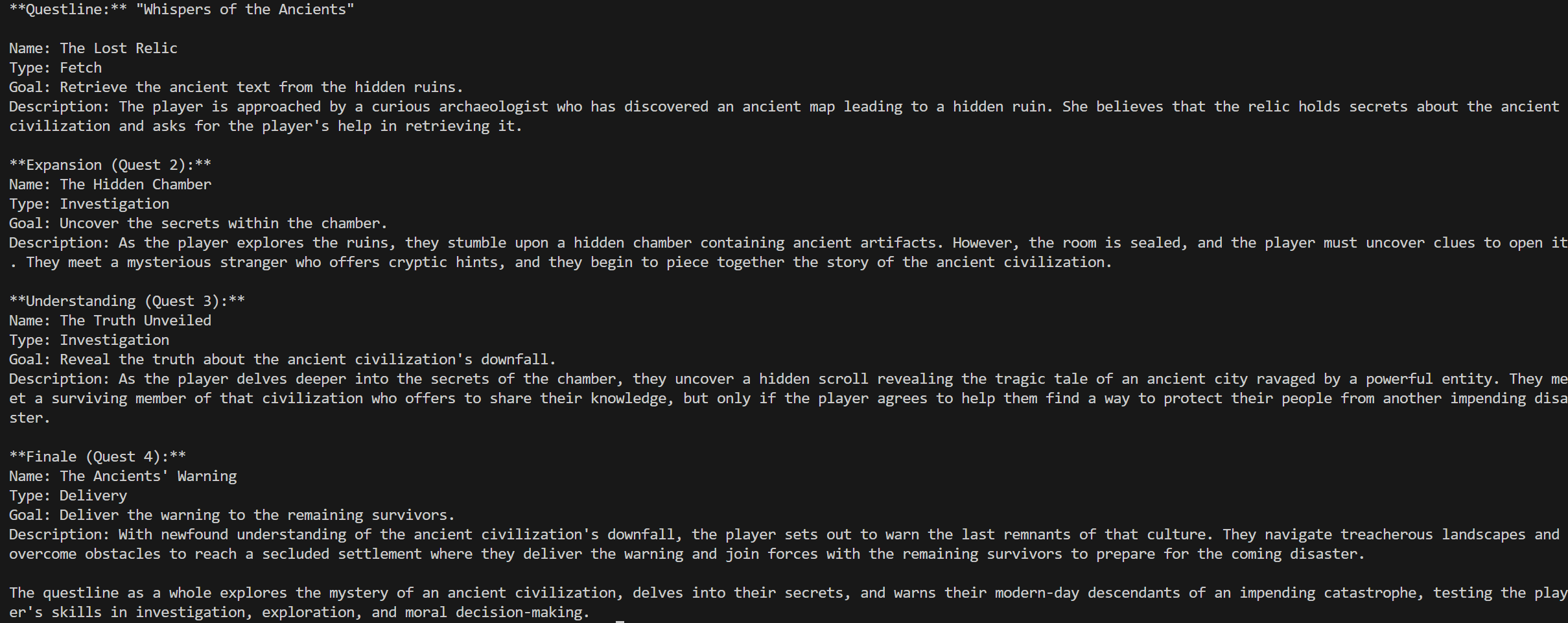
A modular structure for the system was planned during this phase, and preliminary prompts for quest generation were designed. The pipeline was named Campbell-Quest, referencing Joseph Campbell's Hero’s Journey as inspiration for structured storytelling.
🔄 Phase 2: Iterative Design & Implementation
This phase involved multiple development iterations, each targeting a distinct feature or system component:
- LLM Integration with Unity: A Python-based generation pipeline was wrapped using Unity’s Python scripting interface. Initial tests verified cross-language communication and JSON serialization for data handling.
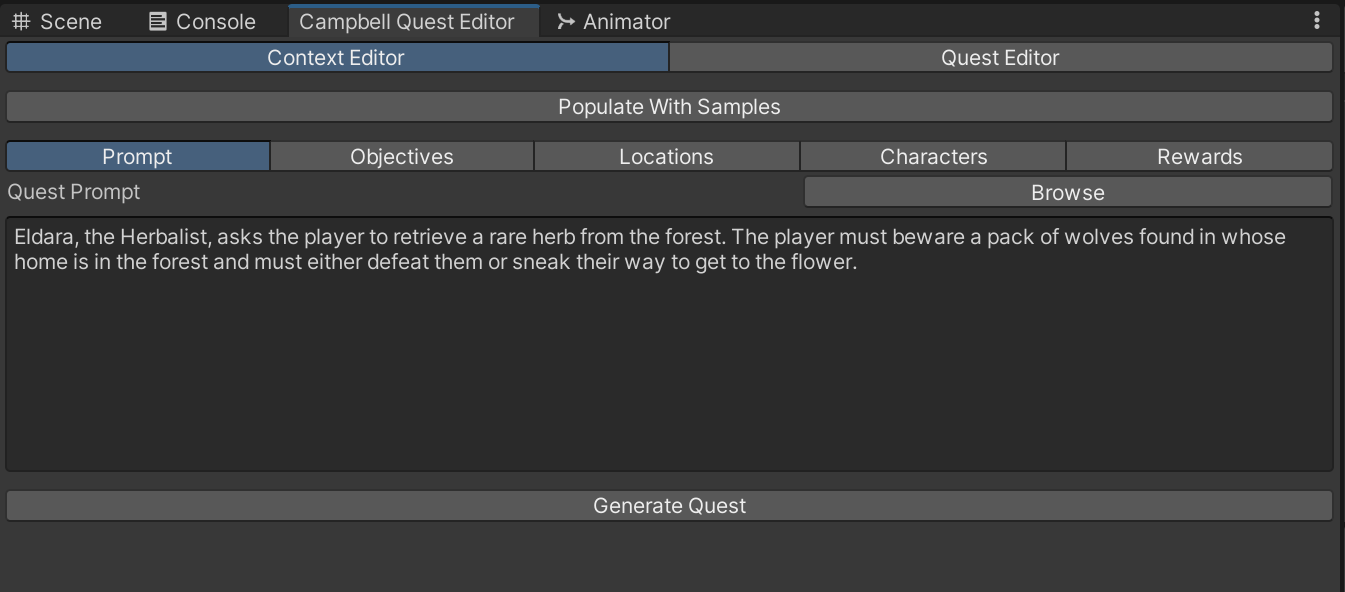
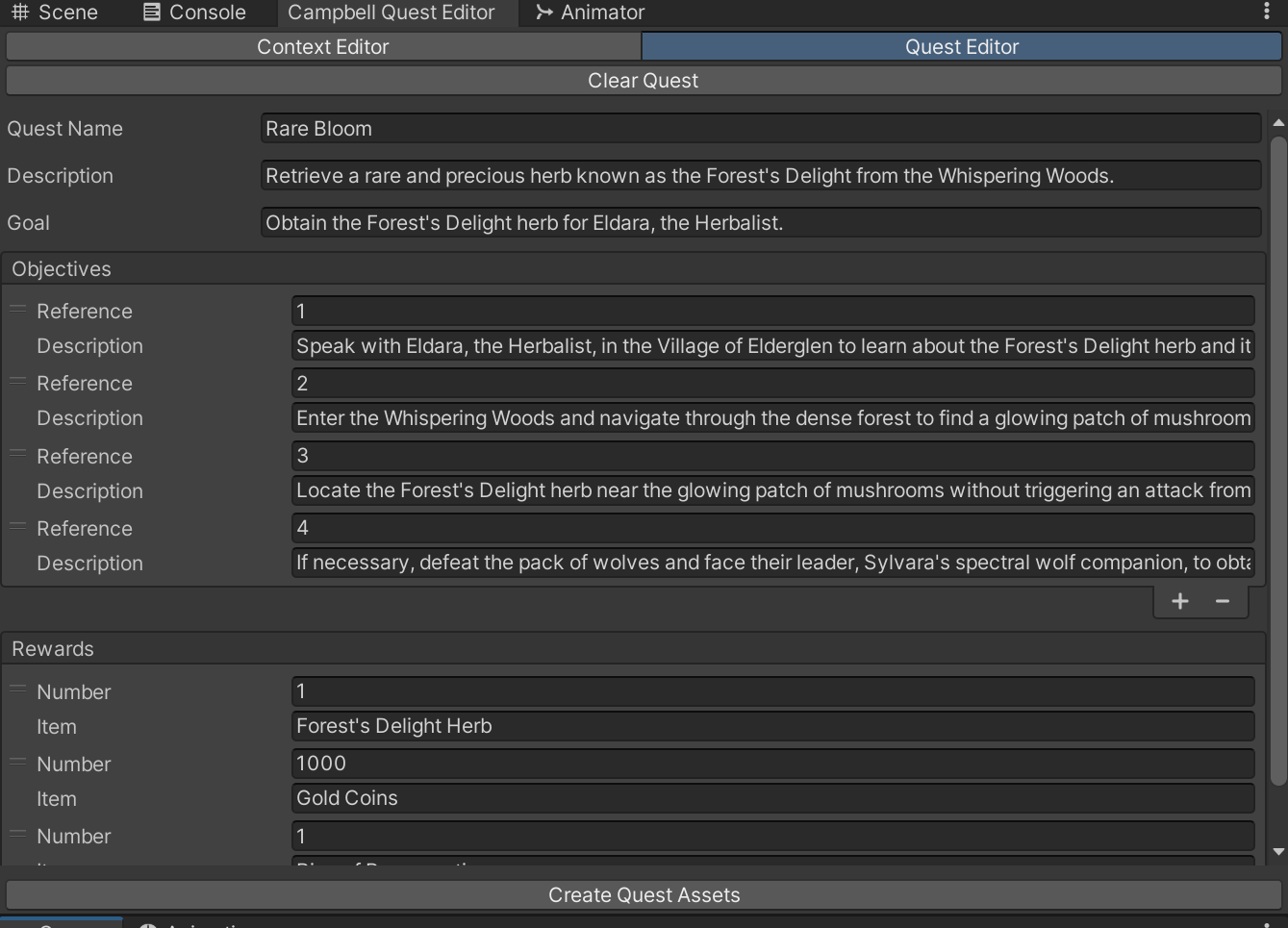
- Quest Editor Tooling: A custom Unity Editor window,
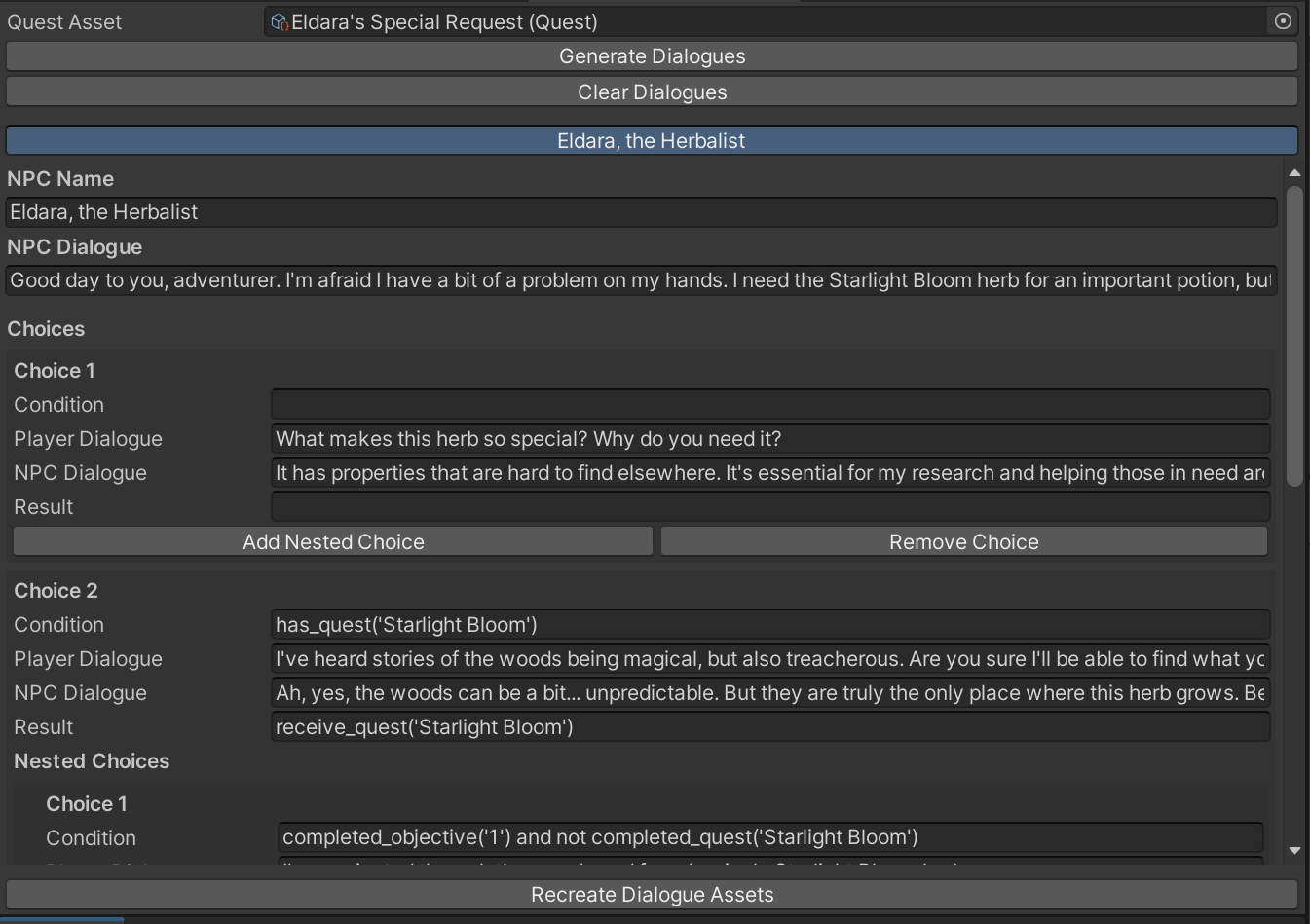
CampbellEditorWindow, was built to let users define prompts, objectives, characters, and locations. Generated content was parsed and converted into ScriptableObjects for seamless asset creation. - Dialogue, NPC, and Item Pipelines: The tool was extended to procedurally generate dialogue trees tied to quest progress, as well as NPCs and in-game items. These were implemented using modular C# classes like
DialogueGenerator,NpcGenerator, andItemGenerator, enabling automated prefab creation and asset linking. - UI Refactor & Modularization: The single editor window was split into four specialized interfaces—Quest, Dialogue, NPC, and Item Editors—each with dedicated processors and generators, improving maintainability and user experience.
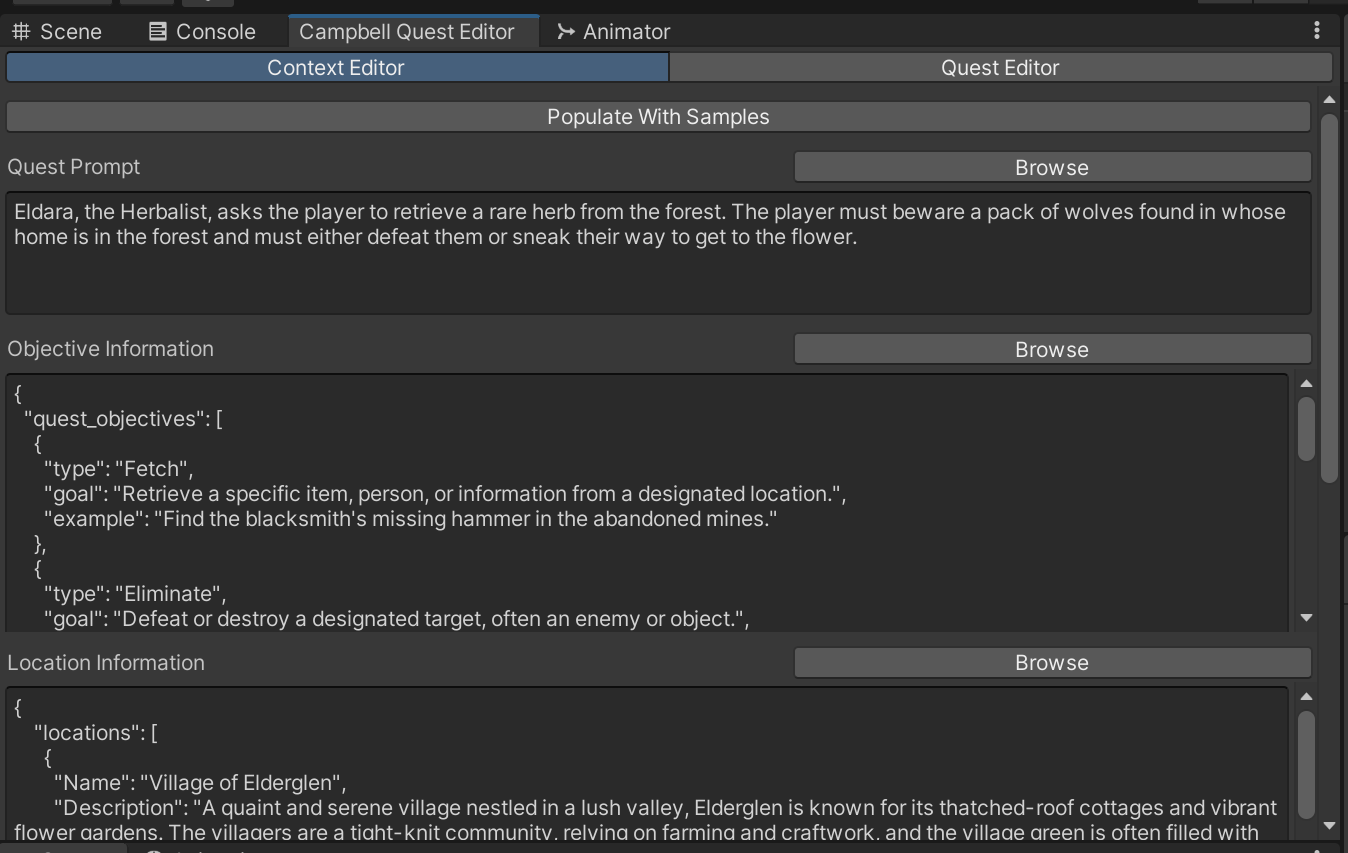
Each iteration included testing within Unity to verify integration fidelity and gameplay coherence.
🧪 Phase 3: Evaluation & Validation
With the system fully functional, focus shifted to assessing the quality of generated quests. Evaluation metrics were established, covering:
- Conciseness & Coherence
- Relevance & Engagement
- Creativity & Narrative Complexity
A LangChain-based evaluation pipeline was implemented using LangSmith and GPT-4 Turbo. This pipeline automated testing across multiple models (Llama3.1, Gemma2, Mistral-Nemo) using structured prompts and response analysis.
Evaluation results informed further refinements, particularly in template design, prompt engineering, and output formatting. The trade-offs between latency, token usage, and narrative quality were also studied to optimize system performance for different use cases.